
I’ve written separately about what the Geopol Forecaster pipeline is and why I built it. This post goes deeper into the simulation design itself — the characters in the snowglobe stage, the personalities programmed into the analytical council, and how world state persistence works across turns. Think of it as the director’s commentary.
The actor roster: 40 characters in search of a conflict
The simulation stage (Stage A) draws from a roster of over 40 geopolitical actors, each defined as an ActorSpec with five components: a persona brief describing their historical decision patterns and worldview, a list of known red lines they won’t cross, a typical response pattern describing how they historically behave under pressure, institutional constraints that limit their freedom of action, and their role and institutional affiliation.
For Iran-Israel focused simulations, the pipeline uses a curated 10-actor core: Ali Khamenei (Supreme Leader), Benjamin Netanyahu (Israeli PM), Donald Trump (US President), the IRGC Command (collective), Hezbollah’s post-Nasrallah leadership, CENTCOM Commander, Mossad Director, IDF Chief of Staff, Russia (Putin/MoD), and Mohammed bin Salman. The extended roster adds another 30+ actors for deeper dives — including the Artesh (Iran’s conventional military, distinct from the IRGC), the Quds Force, IRGC Aerospace Force, IRGC Intelligence, the civilian MOIS intelligence ministry, Iranian dissidents, the quiet dissenting majority inside Iran, diaspora factions (pro-Pahlavi monarchists, general diaspora), the Lebanese government, Lebanese Armed Forces, Houthis, Erdoğan, the Qatari mediation track, the EU, the UN, and specific governments like Germany.
The reason for this granularity is that geopolitical forecasting collapses when you treat states as unitary actors. Iran is not one decision-maker — it’s at minimum Khamenei, the IRGC command, the Quds Force, the Aerospace Force, the intelligence apparatus, and the conventional military, all with different incentive structures and different levels of hawkishness. Israel is not one actor — it’s Netanyahu (with his coalition and legal pressures), the IDF (with its operational assessments), and Mossad (with its covert operational tempo). The simulation needs to model these internal tensions because they’re often where the interesting dynamics emerge.
What a persona actually looks like
Each actor’s persona brief is a few hundred words of compressed analytical profile. Take Khamenei:
“85-year-old cleric holding final authority on all strategic military decisions. Decision-making is consultative but not democratic — relies on a small inner circle including the IRGC commander and Quds Force leadership. Has consistently prioritised regime survival over ideological maximalism when forced to choose (JCPOA acceptance 2015; restrained response after Soleimani assassination 2020; calibrated April 2024 strike on Israel telegraphed in advance via intermediaries). Deep historical memory of the Iran-Iraq war shapes his tolerance for prolonged conflict.”
His red lines: direct strikes on nuclear facilities, strikes on his person or inner circle, and visible regime instability. His typical pattern: absorbs the first blow, signals restraint publicly, authorises proportional retaliation via proxies before direct action. Prefers deniable response when possible. Escalates deliberately, not impulsively.
Compare that to Netanyahu: “Longest-serving Israeli PM. Sees Iran’s nuclear programme as an existential threat and has built his political identity around confronting it. Governs via a narrow right-wing coalition dependent on Ben-Gvir and Smotrich — domestic coalition survival is a permanent constraint. Personally under criminal indictment, which sharpens his incentive to stay in office.” His typical pattern: delays, consults the War Cabinet, then authorises high-signal action with plausible escalation dominance. Will use US strategic cover when available; will act unilaterally if he believes the window is closing.
The personas aren’t trying to be complete biographies. They’re trying to capture the decision-relevant traits — the things that, if you were a fly on the wall in a strategy meeting, would predict what this person does next. Historical decision patterns matter more than demographics. Institutional constraints matter more than ideology.
The interesting edge cases: non-state and diffuse actors
Some of the most interesting persona work went into actors that aren’t traditional state players. The “Quiet Iranian dissenting majority” is defined as “urban, educated, often secular or post-Islamic, economically ground down by sanctions and mismanagement. Loathes the IRGC but also fears chaos, war, and a repeat of Iraq/Syria/Libya.” Their typical response pattern: rallies around the flag when Iran is struck by foreign powers; withdraws legitimacy when the regime overreaches internally.
That actor never fires a missile or issues a diplomatic statement. But their passive acquiescence or withdrawal of legitimacy is what ultimately constrains or enables regime moves. The simulation needs them because without modelling domestic legitimacy dynamics, you’d get forecasts that treat authoritarian regimes as frictionless decision-making machines (which is what most punditry does, and why most punditry is wrong about internal regime dynamics).
Similarly, the Houthi persona captures something punditry often misses: “Absorbs US/UK strikes without strategic damage; Yemeni population base is mobilised by conflict, not deterred.” The Houthis don’t respond to military pressure the way Western doctrine assumes because the cost-benefit calculus is different when your population base sees taking strikes as legitimacy-enhancing rather than punishing.
The sealed-off reasoning model
The most important architectural decision in Stage A is what actors cannot see. Each actor receives only the referee-authored world state and their own private memory from prior turns. They never see raw news feeds. They never see Tavily search results. They never see other actors’ private assessments. This is strict — enforced at the prompt level.
Why? Because if actors could see the news, the simulation would collapse into “inference over the news feed” — which is exactly what Stage B (the analytical council) already does. The whole point of having two stages is that they generate independent signals. The simulation models what actors would do given their known incentive structures; the council models what’s actually happening in the world. The divergences between these two signals are the diagnostic payload.
Each actor outputs a structured JSON response with five fields: a private assessment (their honest internal view), a public statement (what they say publicly), a concrete action (one specific thing they commit to doing), red lines they considered, and a confidence level. The rule is explicit: hedging is not permitted. The actor must commit to a specific action consistent with their historical pattern, or justify the deviation from within the persona’s own logic.
How world state persistence works
The simulation runs across multiple timesteps (typically three: +24 hours, +72 hours, and +2 weeks, though this is configurable). World state persistence is the mechanism that connects these timesteps into a coherent narrative arc.
Turn 0 initialisation: The world state starts as a combination of static base context (the conflict background), the forecast question, and a terse RSS/ISW news seed frozen into the initial state. A header declares: “From this point on, the world state is authored exclusively by the referee.”
The turn loop: At each timestep, all actors receive the current world state and make their decisions in parallel (via asyncio.gather, so all 10 actors reason simultaneously). Then the referee — a separate LLM call with its own system prompt — reads the prior world state plus all actors’ public statements and concrete actions, and narrates the resulting new world state in up to 500 words of prose plus a structured block listing active actors, recent events, and open tensions.
The referee has strict rules. It cannot invent consequences that don’t follow directly from the actions each player committed. If two actions are logically incompatible, it applies authority-precedence: the action from the actor with higher authority in their own lane takes effect (Khamenei authorises Iranian action; Netanyahu authorises Israeli action). It can note second-order effects only if they’re clearly implied by the stated actions plus existing context.
Private memory: Each actor accumulates a private memory trail of their own prior assessments and actions — capped at 4,000 characters to prevent context bloat. Critically, this is private: actor A can never read actor B’s memory. Each actor remembers only their own trajectory through the simulation. This prevents the kind of information leakage that would make the simulation degenerate into a consensus-seeking exercise.
After all timesteps complete, the entire trace is compacted and sent to a summarisation call that extracts the dominant trajectory, divergent trajectories, per-actor behaviour patterns, empirical probabilities, emergent dynamics, and flags for the council to verify against fresh data.
The six analytical lenses
Stage B uses six lenses, each a system-prompted persona over the same base model. The lenses aren’t just labels — they’re distinct analytical directives that force genuinely different reasoning patterns:
Neutral: “Provide your honest, unbiased assessment of how this conflict will evolve. Do not lean optimistic or pessimistic.” The baseline. Tends to produce the most data-grounded assessments but can default to splitting the difference.
Pessimistic: “Model the worst-case scenarios. Focus on escalation paths, failed diplomacy, and dangerous miscalculations.” Consistently produces the most detailed escalation ladders and timeline-specific predictions. The peer review process has rated this lens highly for specificity.
Optimistic: “Model the best-case scenarios. Focus on de-escalation paths, diplomatic breakthroughs, and restraint by actors.” This is the lens that has performed worst in peer review. It tends to hedge so much that it barely differs from Neutral — a finding I think says something interesting about how LLMs handle optimism under adversarial prompting. It’s easier to be specifically pessimistic than specifically optimistic.
Blindsides: “Identify low-probability but conceivable pivots and black swan events that could fundamentally change the trajectory.” The most creative lens. It’s identified scenarios the other five consistently miss: Strait of Hormuz shipping accidents, radiological catastrophes from sabotage gone wrong, and psychological breaking points where ideological factors override strategic rationality.
Probabilistic: “Use probabilities and historical precedent to make mathematically rigorous predictions. Assign explicit probability ranges to outcomes.” Consistently rated top or second by peer review. Produces Bayesian frameworks with explicit likelihood ratios and pathway decomposition. The most calibrated of the six.
Historical: “Make predictions solely through the lens of historical actor behaviour in similar circumstances. Deliberately ignore statistical weight of evidence to produce a differentiated, historically-grounded response.” The instruction to “deliberately ignore statistical weight” is intentional — it prevents this lens from converging with Probabilistic. It produces base-rate reasoning from historical analogues (Shah’s Iran, East Germany, Romania, Argentina) that the other lenses don’t surface.
The blind peer review
After all six lenses produce their forecasts independently, they review each other. Each lens receives all six answers anonymised as Response A through F — they don’t know which perspective wrote which answer. They critique each response on specificity, fidelity to evidence, internal consistency, and lens-appropriate sharpness (is it actual analysis or hedge-speak?). Each reviewer ends with a ranked list from best to worst.
This is ported directly from Karpathy’s llm-council design, and it’s the step that adds the most value relative to its cost. The peer review consistently identifies when a lens has drifted from its directive (the Optimistic lens being insufficiently optimistic is a recurring finding), when predictions contradict the evidence cited in their own analysis, and which lenses produced the most actionable forecasts. The chairman reads both the original answers and the peer reviews, which means weak analysis gets flagged before it reaches the final synthesis.
The chairman synthesis
The chairman is a single LLM call with a structured output mandate. It reads the original context bundle (base context + fresh data + simulation summary), all six lens answers, and all six peer reviews, then writes the final report directly in markdown. The report has a mandated structure: headline forecast with probability band, key predictions table, convergence analysis, divergence analysis, simulation blind-spot check, per-lens contributions with peer review scores, and a simulation appendix.
The chairman writes at temperature 0.5 with a 12,000-token output budget. The output is the deliverable — there’s no downstream editing or formatting stage. This is a deliberate design choice: the chairman has to synthesise, not summarise. It has to make calls about which lenses were right, which predictions are high-confidence, and where the simulation and research disagree. Synthesis under constraint is the hardest reasoning task in the pipeline, which is why it’s the only stage that gets the full context window.
Monte Carlo foundations and probability calculation
The probability estimates that appear in the final report aren’t arbitrary — they emerge from a layered process that borrows from Monte Carlo simulation methodology, even though the current pipeline runs a single simulation pass rather than hundreds.
In classical Monte Carlo forecasting, you run the same scenario many times with randomised parameters and count how often each outcome occurs. If you run 1,000 simulations and a ceasefire collapses in 780 of them, you have a 78% empirical probability of collapse. The Geopol Forecaster was designed with this in mind — the configuration includes an MC_RUNS parameter that controls how many independent simulation passes to execute. Each run uses temperature 0.8 for actor decisions, which introduces stochastic variation: the same actor facing the same world state won’t always make the same choice, just as real decision-makers don’t always react identically to identical stimuli.
In practice, I’ve been running single passes (MC_RUNS=1) for the initial forecast runs because each pass involves ~60 LLM calls and the marginal insight from additional runs diminishes when you already have a six-lens council providing analytical diversity. The simulation’s post-run summarisation step extracts empirical_probabilities — a dictionary mapping events to float probabilities derived from actor behaviour patterns and confidence levels within the trace. When multiple runs are executed, these probabilities are aggregated across runs, giving true frequentist estimates.
The council stage adds a second probability layer. Each of the six lenses produces independent probability estimates for each prediction. The chairman then synthesises these into a final probability band, weighting by peer review quality scores. The result is a probability that reflects both the simulation’s game-theoretic reasoning (what actors would do) and the council’s research-grounded analysis (what the evidence suggests). The 90% credible intervals reported in the final forecasts come from the spread across lenses — if all six lenses agree within a narrow band, the interval is tight; if they diverge significantly, the interval widens to reflect genuine analytical uncertainty.
This is conceptually similar to how prediction markets work: diverse independent estimators, each with access to different information or analytical frameworks, producing estimates that are aggregated into a consensus. The difference is that instead of hundreds of human traders, the “market” is six prompted personas plus an actor simulation, all grounded in the same frozen data bundle.
Visualisations from recent runs
To give a sense of what the pipeline’s outputs look like in practice, here are some visualisations from two recent forecast runs.
From the Iran-Israel ceasefire forecast (April 9, 2026):
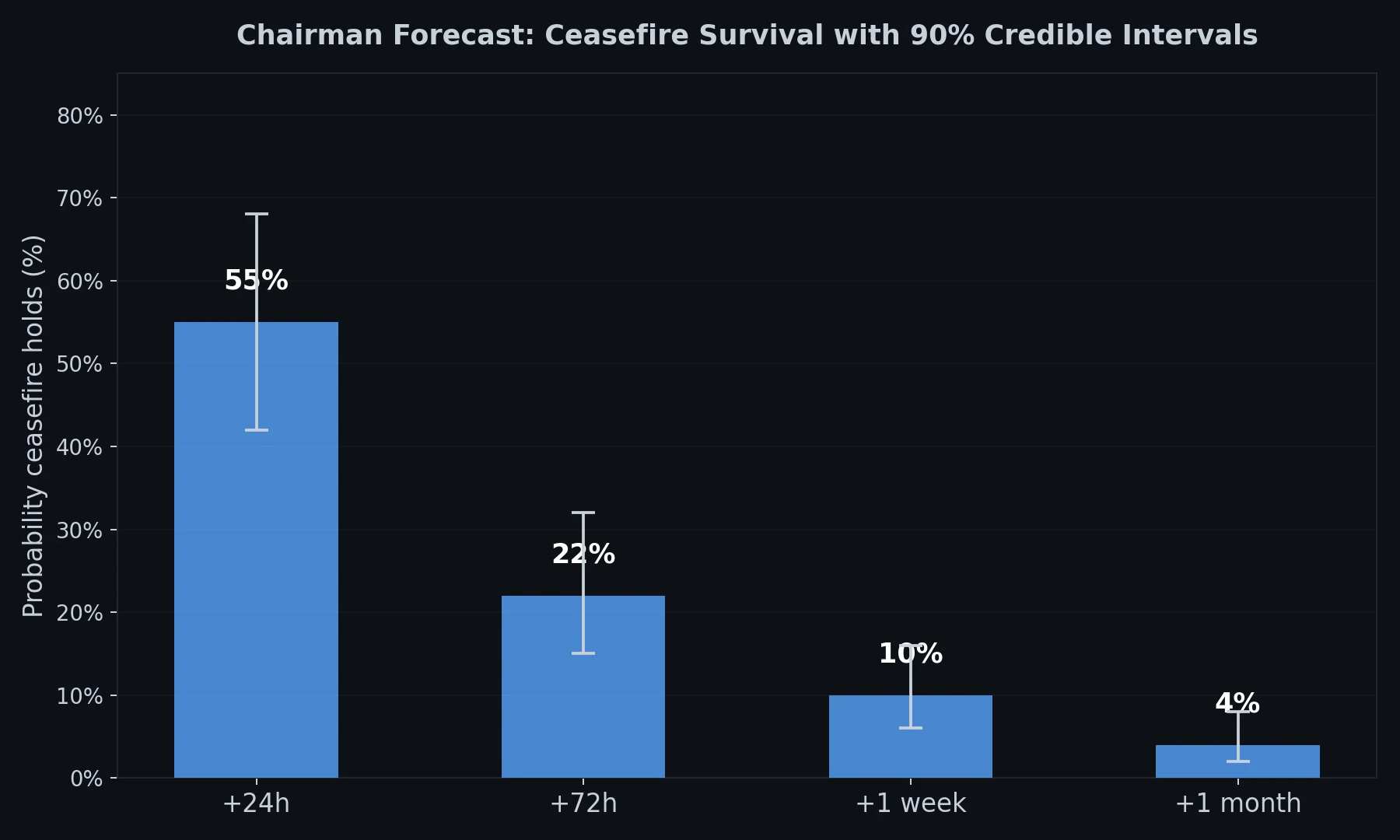
The chairman’s headline probabilities across all time horizons, showing the steep decay from 55% at 24 hours to 4% at one month.

Convergence between Stage A (actor simulation) and Stage B (council) at the critical 72-hour window.
From the Iran regime change forecast (April 10, 2026):
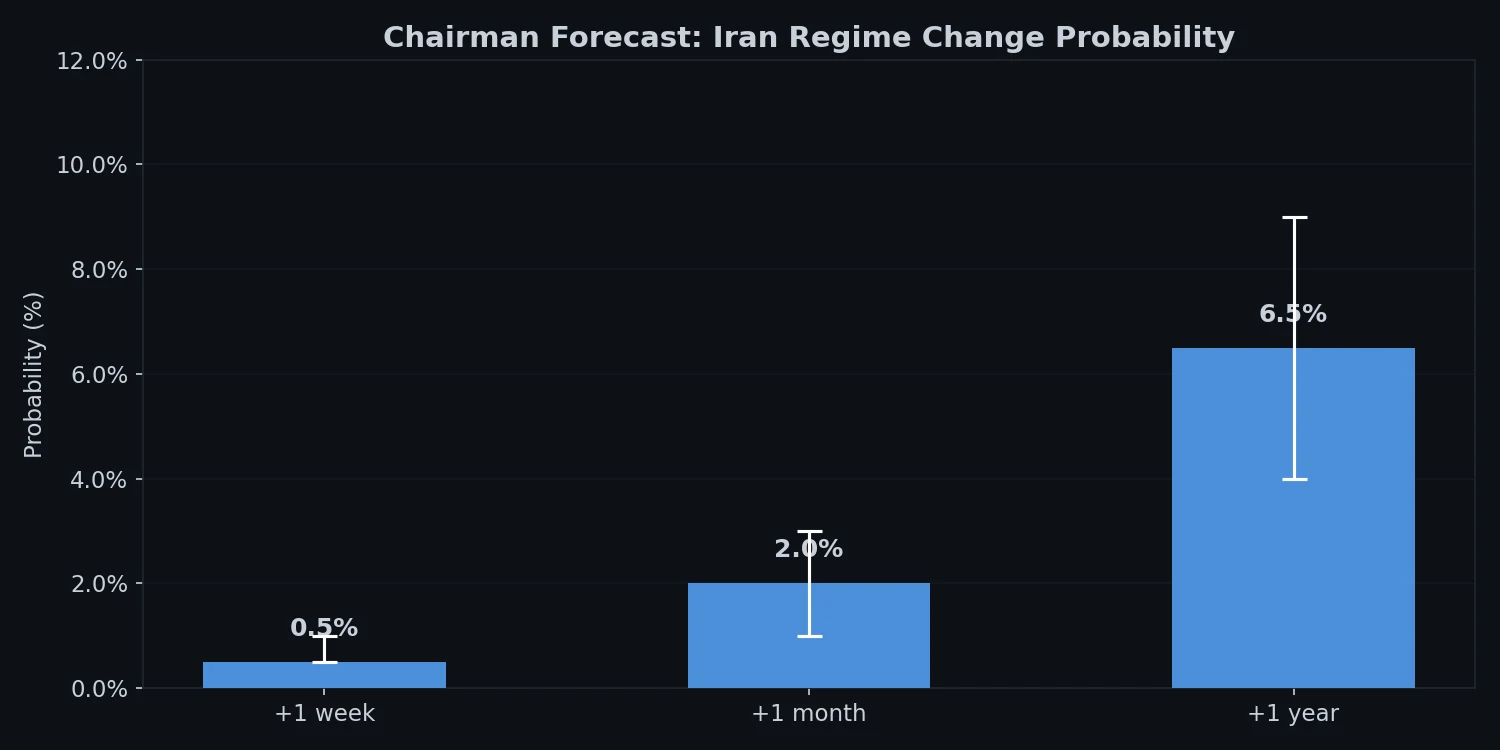
Chairman’s forecast across one-week, one-month, and one-year horizons.
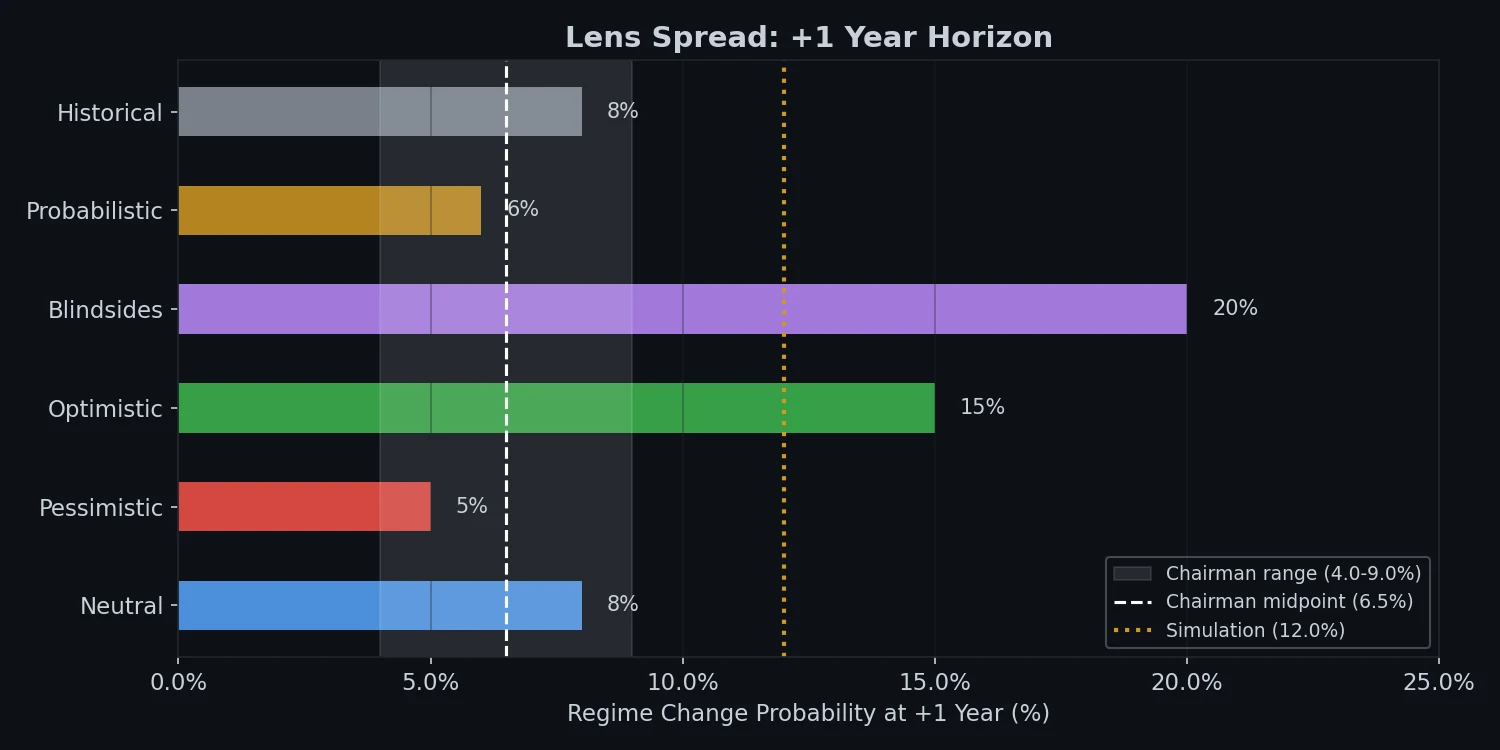
One-year lens spread showing how the six analytical perspectives diverged — the Blindsides lens estimated 15-20% while Probabilistic and Historical converged around 3-7%.
Published forecast runs
Each forecast run is published as its own GitHub repository with the full data — simulation transcripts, all six lens analyses, blind peer reviews, frozen news bundles, and the chairman’s report:
Iran-Israel Ceasefire Prediction (April 9, 2026) — assessed the durability of the April 8th ceasefire. Blog post: AI Forecasting the Iran-Israel Ceasefire: A 4% Chance of Holding
Open-sourced geopolitical forecast: Iran-Israel-US ceasefire durability assessment (09/04/2026). Two-stage pipeline (Snowglobe + LLM Council) with 38-actor simulation and 6-lens analytical panel.
Iran Regime Change Forecast (April 10, 2026) — assessed forced regime change probability. Blog post: AI Forecast: Forced Regime Change in Iran at 4-9% Within a Year
Geopol Forecaster run: probability of forced regime change in Iran (+1 week / +1 month / +1 year). 10-actor simulation + 6-lens council. Headline: <1% / 1-3% / 4-9%.
All published runs are indexed at the Geopol Forecaster runs page.
The stack
The same tools power all of this:
Stage A: IQTLabs/snowglobe — In-Q-Tel’s open-source geopolitical game engine (Apache 2.0)
Open-ended wargames with large language models
Stage B: karpathy/llm-council — Andrej Karpathy’s 3-stage deliberation protocol with blind peer review
LLM Council works together to answer your hardest questions
LLM: Claude Sonnet 4.5 via OpenRouter
Orchestration: LangGraph with SQLite checkpointing
Build resilient agents.
News: Tavily search + RSS/ISW feeds
Memory: Pinecone vector archive
Full source: github.com/danielrosehill/Geopol-Forecaster
Experimentary prediction analysis for real world events (Iran Israel)
