Get Cloud LLMs To Recommend Local LLMs (How To)

An extremely simple but effective approach to leveraging the ability of context to dramatically improve LLM outputs can be demonstrated by asking an LLM to recommend a good local LLM that you can run on your hardware (like getting LLMs to optimise prompting strategies for themselves, this feels a bit weird and ‘meta’).
Given how quickly the LLM space is evolving, I recommend using something like (yes, it’s simple but effective) GPT-4o via the web UI.
It stands some chance of keeping up with what’s going up on Hugging Face (etc). Anything with a training data cutoff beyond (say) six months ago is probably - in AI terms - already too old and fuddly for this task.
Here’s how this prompting strategy works as I’ve been refining it:
Step 1: Note your hardware as a “context snippet”
Firstly, I recommend setting up a context repository just for this purpose.
If like me you use LLMs both for personal and professional purposes, set up a separate ‘context repo’ for both.
It doesn’t have to be anything fancy (and it certainly doesn’t need to be RAG or stored as vectors for small insertions). A glob of markdown files or JSON docs versioned through Github more than gets the job done:
I’ve experimented with noting my hardware parameters in both JSON format and (latterly, after I moved to a new OS) by being a bit lazy and just taking a screenshot of a previous note.
Like this:
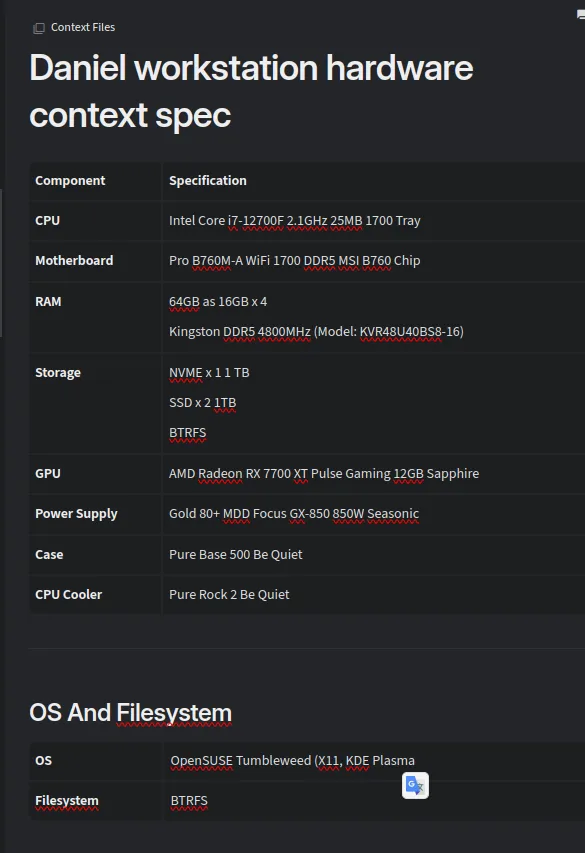
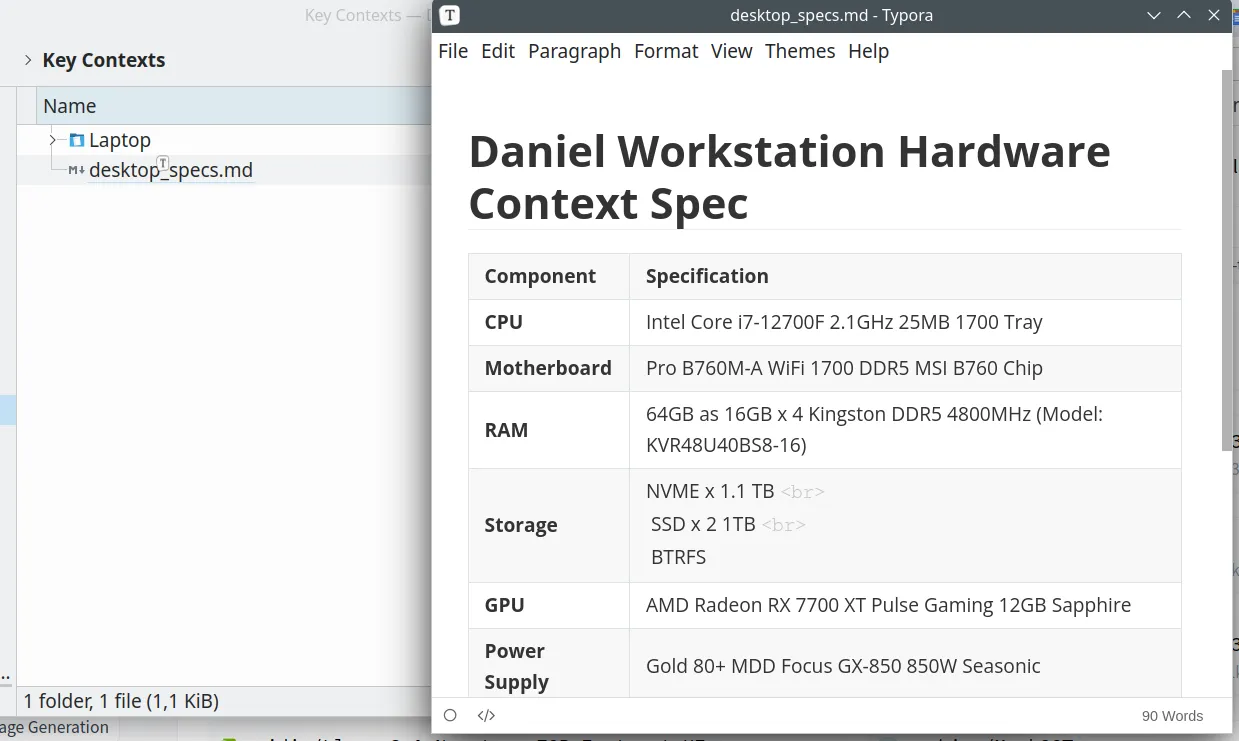
Being a bit less lazy, you can denote your specs as a markdown doc, formatted as a table, like this:
But commercial LLMs’ image-to-text capabilities are so impressive that - until I see decisive evidence to the contrary - I’m going to say “it really doesn’t make a difference”.
Prompting with context
Let’s say you’re using a web UI (I’ll use Perplexity for this demo):
All you have to do is drag and drop the JSON or .md or .PNG (it doesn’t really matter) into the prompt window.
Like this:
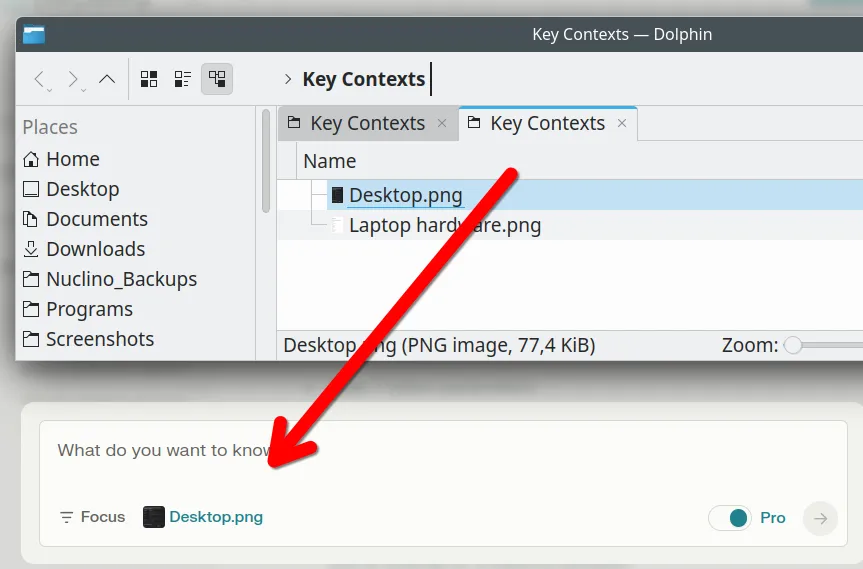
With one quick drag and drop operation, you’ve just provided some quite detailed contextual info to guide this inference!
In my case, it provides details of the hardware spec of my desktop and also the exact type of Linux distro that I use.
When trying to* find compatible hardware or software, these few datapoints supplied together (what GPU? What motherboard? What distro? What PSU? OpenSUSE LEAP or Tumbleweed?) make an absolute world of difference.
This simple technique (I’m resisting the urge to describe it as a “hack”) is where LLMs-with-context run rings around both traditional search engines and my ability to filter (say) a piece of RAM I want to buy against a multitude of background parameters that all guide compatibility.
In this context (local LLM model selection) by providing details of what hardware you’re working with (whether desktop or server), you let the LLM see which GPU you have (from which it can infer the VRAM from a spec sheet in its training data if it’s not provided); your CPU; your OS; etc.
These all help the LLM zone in on making recommendations that are suitable to your current hardware (buy an upgrade? Easy! Just edit your context note and carry on prompting!).
Finally: the prompt
As ever, the key with getting good results here is to be as specific as you can be (much more so than you would be with a human):
Here’s one I used to ask for a code generation LLM:
Recommend some local LLMs that I can run comfortably on this hardware using LM Studio.
Suggest LLM that have performed well on evaluation benchmarks, ideally conducted in the last year.
I am looking for an LLM that is proficient at generating compliant Python and Bash scripts
For every model that you suggest, provide the model name, the variant you recommend, and details about why you recommended it.
With modern LLMs, you don’t need to be massively specific.
But on older variants, like the early iterations of the GPT models, you might need to get down into the weeds of providing objective parameters to explain exactly what running “comfortably” means in this context (as after all, it’s a linguistic colloquialism - one of countless colloquialisms that we use without a second thought without realising that, from a strictly literal standpoint, they often make little sense).
Is 80% VRAM consumption “comfortable”? Or does “comfort” from the perspective of the GPU mean that it’s not going up in smoke? What about 70%? You get what I mean. Thankfully, for the most part, we no longer need to be that robotic in … prompting robots. As we’re about to see, modern LLMs are able to determine context … even when we’re deliberately trying to set context!
Do I need to tell it to use the screenshots as context?
At the time of writing, I use (mostly) GPT-4o and Claude Sonnet 3.5 with a smattering of Gemini (I periodically think “it’s Google so it has to be good, right?” and then trudge off quietly disappointed).
Cliff Notes: I have not found with either that you need to explicitly state things like:
I have uploaded an image with my hardware specifications.
Use this as context for your generation.
But if you’re not worried about tokenisation (and with a prompt like this, that’s not likely to be a concern) you could tack that on to play it safe.
Example output
So here’s roughly where we land with this strategy.
Prompting on Perplexity (set to model: GPT-4o):
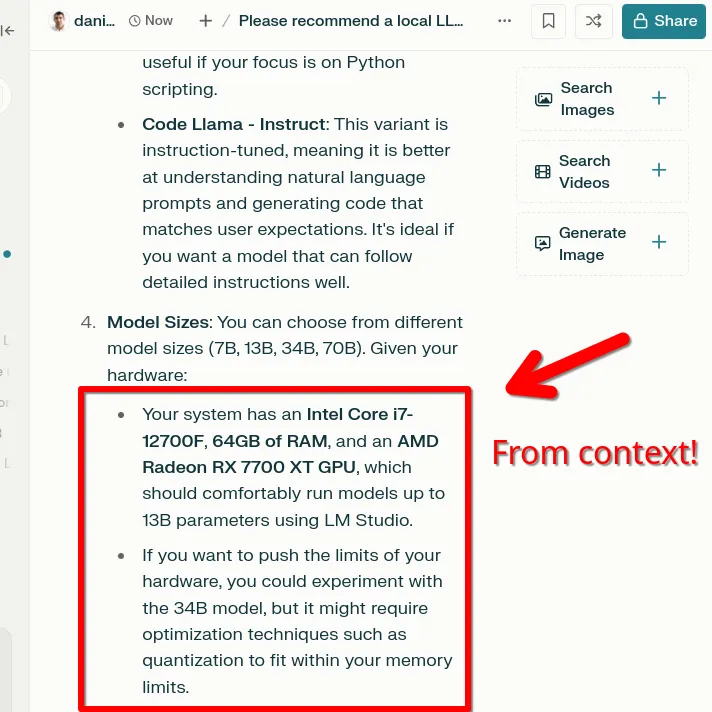
The output demonstrates that the LLM has parsed the image I supplied as context and informed its response through that lens correctly.
If it’s your first time playing around with what I call the poor man’s RAG (ie, dropping in files to set context), then you can chain a simple evaluation prompt before going for the target.
You might ask something like:
I've uploaded my hardware spec.
Before I ask you the next question, can you confirm that you've been able to parse the text and understand what hardware I have?
And the LLM will rote back with something like this in response:
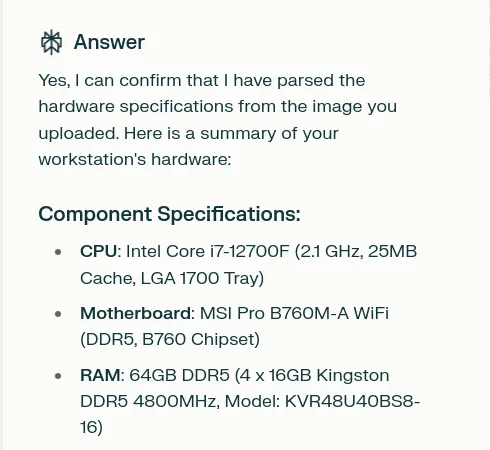
In the screenshot below, you can see that the LLM has considered my workstation’s GPU, RAM, and CPU when making its recommendations. Note: this was from V1 of the prompt. I didn’t specify anything like “please use this screenshot as context”. The LLM was smart enough to know that that was the presumed intention in my providing the image like that. I (still) think that’s pretty cool!
Final Tip: Ask For Both Models And Variants
Quantization being a complicated topic (and if I told you that I understood, I’d be bluffing), I often find it useful to ask the LLM to be very specific in recommending not only a model but also a specific variant.
Given that you’ve supplied your hardware as context, you may as well tack this on to the prompt.
I might write something like:
For every recommendation, provide both the model that you recommend and the specific variant.
And an example never hurts in boosting accuracy (in fact, research shows that a single example boosts accuracy tremendously; one of several highly actionable nuggets I picked up from “Prompt Engineering For Generative AI” by James Phoenix and Mike Taylor. I highly recommend!)
For example, don't recommend "Wizard Coder Python". Rather, recommend "Wizard Coder Python 7B V1.0 GGUF"
By: Daniel Rosehill

Creative Commons Attribution 4.0 International License